SLA and Status Page Best Practices for Border Crossing Solutions

Border-crossing compliance is now a real-time problem. A single outage in the eligibility API that powers your checkout can snowball into abandoned carts, denied boardings and regulatory fines. To protect revenue and reputation, travel brands need two pillars of operational transparency: a rock-solid Service Level Agreement (SLA) and a public status page their teams actually trust. Here is a practical playbook for getting both right when you work with visa-management and border-crossing solutions.
Why SLAs and Status Pages Matter in Border-Crossing Tech
- Booking flow dependency – Every fare search or seat selection may call an eligibility endpoint to display whether a passenger needs an electronic visa, an ETA or nothing at all. Downtime is a direct conversion hit.
- Regulatory penalties – Airlines can be fined up to USD 5,000 per mis-boarded passenger on some routes. An SLA that enforces data freshness greatly reduces that risk.
- Ancillary revenue – If you sell eVisas inside the flow, every minute of latency or outage reduces attach rate. A status page allows revenue managers to quantify impact and trigger compensation.
Gartner estimates that each hour of API downtime in the travel sector costs between USD 8,000 and 25,000 in lost bookings and rework. A well-crafted SLA shifts that cost away from the merchant and onto the vendor if targets are missed.
Core SLA Metrics for Border-Crossing APIs
| Metric | Definition | Recommended target | Why it matters |
|---|---|---|---|
| Availability | Percentage of minutes per month the API is reachable and returns a 2xx/4xx (not 5xx) | 99.95 % (21 min downtime per month) | Keeps checkout and post-booking flows live |
| p95 Latency | 95th-percentile time to first byte for an eligibility request | ≤ 300 ms | Prevents slow forms and drop-offs |
| Data freshness | Time between a government rule change and its reflection in the API | < 2 hours for breaking changes | Avoids boarding denials |
| Processing time | Mean time from visa form submission to vendor confirmation sent to government portal | < 30 s | Critical for same-day and last-minute bookings |
| Support response | Initial human response times by severity (P1 ≤ 15 min, P2 ≤ 1 h, P3 ≤ 6 h) | 24 × 7 × 365 coverage | Reduces queue build-up |
| Security posture | Independent certifications and audits | ISO 27001, SOC 2 Type II, GDPR | Protects PII and payment data |
| Recovery Time Objective (RTO) | How long until service is restored after a total outage | 1 hour | Limits disruption |
| Recovery Point Objective (RPO) | Maximum data loss window | 0 min (real-time replication) | Preserves applications in flight |
Remedies and Transparency Clauses
- Service credits that escalate from 10 % to 100 % of monthly fees when uptime falls below tiers.
- Root-cause analyses (RCA) published within 48 hours of any Severity 1 incident.
- Penalties for stale data (e.g., if a change in ETIAS rules is not reflected in production within the agreed window).
Tip: reference SimpleVisa’s public SLA template for clear wording on incident classification and credit calculation.
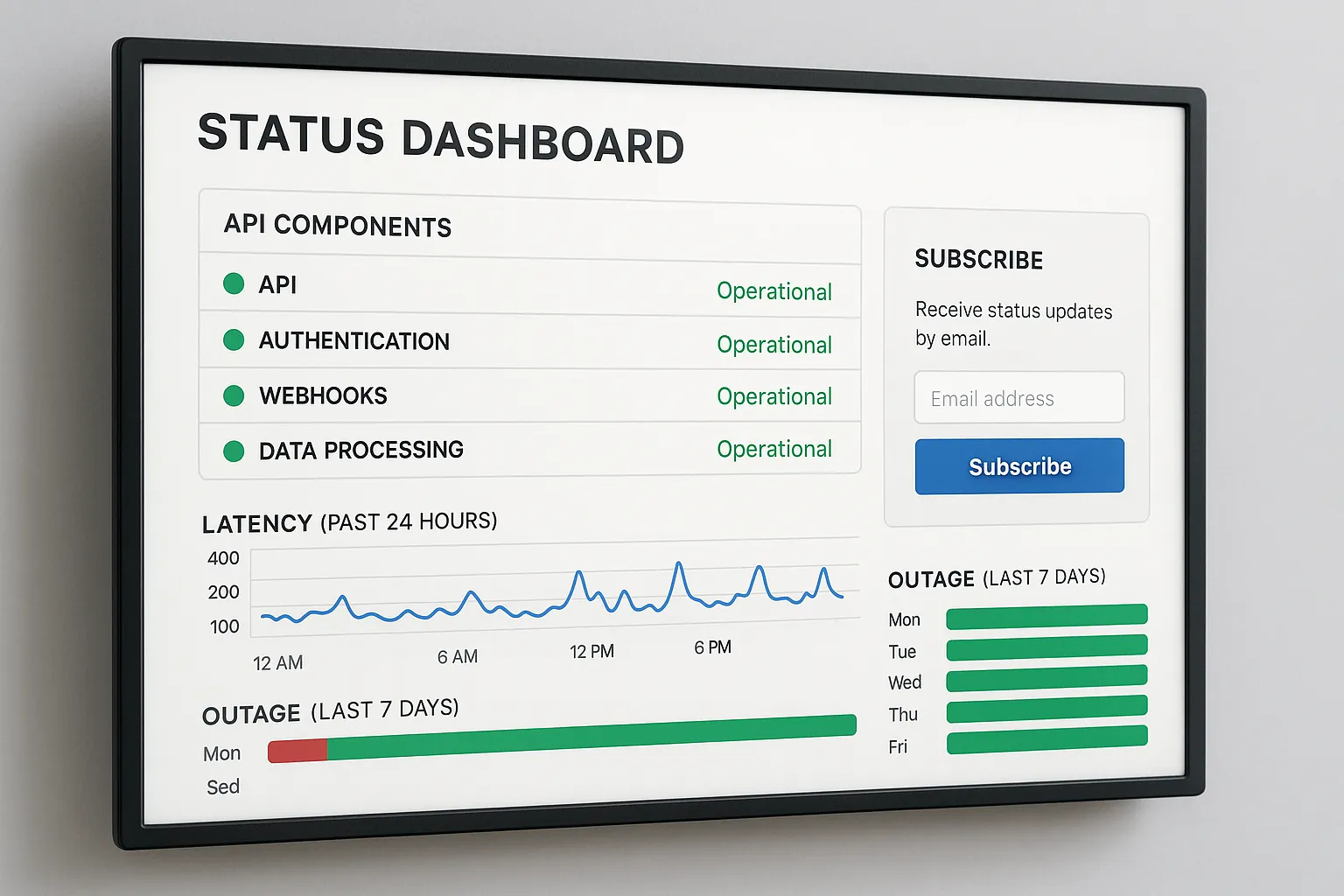
Designing a Status Page Customers Will Use
A status page is more than a vanity uptime badge. Think of it as the single source of truth for everyone from your NOC to a call-centre agent reassuring a stranded family.
Mandatory Components
- Component-level health – Split by API clusters (eligibility, application, payments, webhooks) and regions. Component granularity prevents over-reporting.
- Realtime metrics – Current latency, error rates and queue depth. Aggregate into a “traffic-light” view for non-technical staff.
- Historical uptime charts – 90-day and 12-month views support partner audits and procurement renewals.
- Incident log – Timestamped updates with impact scope, mitigation steps and final RCA links.
- Maintenance calendar – Scheduled maintenance with at least seven days’ notice and automatic reminders.
- Subscriptions – Email, SMS, webhook and RSS so partners can wire alerts into Slack, Opsgenie or Zendesk.
- Status API – A lightweight JSON endpoint (
/status.json) developers can poll to surface warnings inside their own dashboards.
Nice-to-Have Extras
- Multi-language incident updates (important for global OTAs).
- Public SLA tracker that shows the running uptime percentage versus the guarantee.
- Performance probes from major traveller origin regions to reveal local ISP issues.
Operational Best Practices
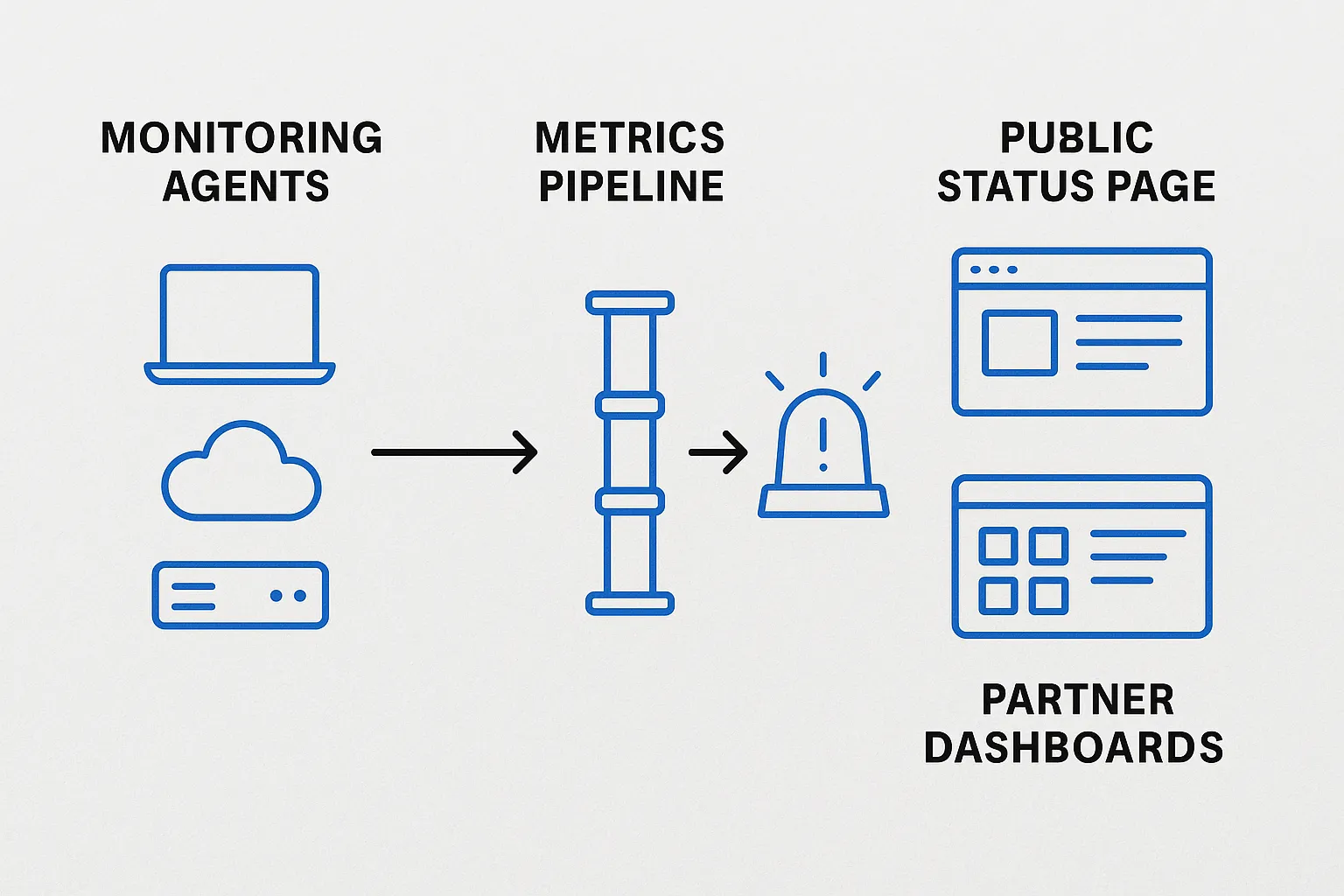
- Measure SLIs continuously – Use internal monitoring to feed the external status page automatically. Manual updates invite human error.
- Drill incident comms – Run quarterly tabletop exercises where engineers and comms simulate a P1 outage and draft updates under time pressure.
- Automate escalations – Tie breach detection to PagerDuty and create Jira tickets with the SLA clause pre-filled. No manual copy-paste.
- Version your SLA – When you add new visa types or geographies, refresh metrics and give partners 30 days’ notice before enforcement.
- Close the loop on partner impact – After every incident, quantify lost bookings or extra call-centre workload and feed that data into UX backlog prioritisation.
Mini Case Study: Transparent Uptime Boosts Conversion
A mid-size European OTA integrated SimpleVisa’s eligibility API in mid-2024. After launch they noticed sporadic drop-offs during weekend spikes. By enforcing a 300 ms p95 latency SLA and exposing component-level status to their revenue-management team, they:
- Reduced form-abandonment rate by 24 % within two sprints.
- Lifted eVisa attach rate from 8.1 % to 10.6 % (worth ~USD 180K ARR).
- Cut visa-related support tickets by 37 % thanks to proactive incident alerts.
Read the full metrics breakdown in Why Border Crossing Solutions Are the Next Big Ancillary Opportunity.
Implementation Checklist
- Map every customer journey touch-point that calls the border-crossing API.
- Assign business impact tiers (checkout, post-booking, back-office) to set proper SLIs.
- Draft SLA clauses covering availability, latency, data freshness, security, support, RTO/RPO and remedies.
- Choose a status-page platform or self-hosted solution with component feeds and multi-channel alerts.
- Wire internal monitoring (Prometheus, Datadog, New Relic) to push metrics automatically.
- Schedule quarterly chaos tests and communication drills.
- Publish the SLA and status page URLs in your partner onboarding pack and Developer Portal.
Final Thoughts
In 2025, reliable border-crossing data is as critical as seat inventory or payment authorization. A tight SLA backed by an honest, data-driven status page transforms outages from brand-damaging surprises into manageable events. Whether you integrate through a no-code widget or a full travel API, demand transparency up front—and make sure your own teams are prepared to act on it.
SimpleVisa’s platform was built with these best practices at its core: 99.95 % availability across five regions, real-time rule updates, ISO 27001 and SOC 2 compliance, and a public status page that exposes every component’s health. If you want to see how it fits into your 2025 travel tech stack, book a demo today and get a copy of our SLA template in your inbox.